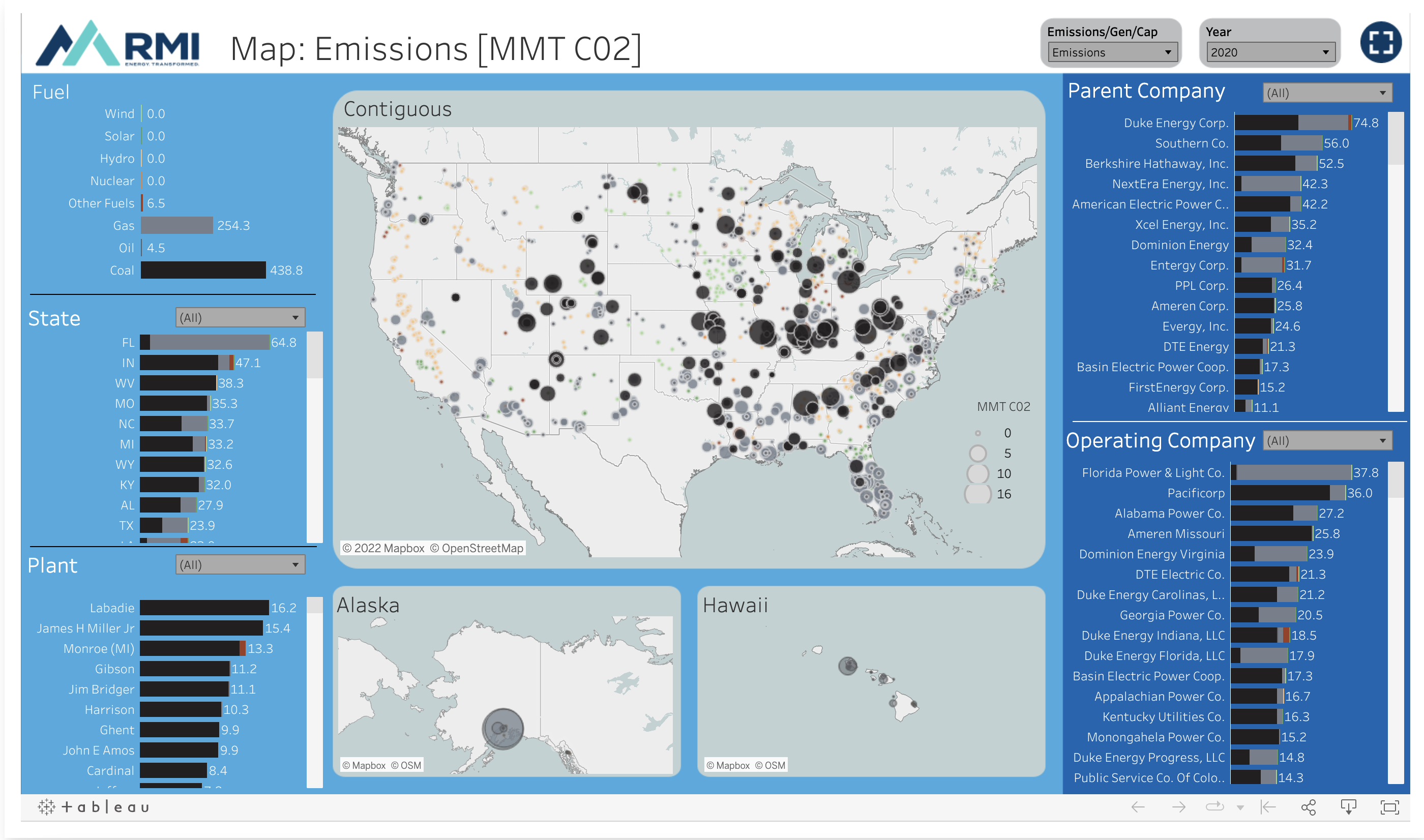
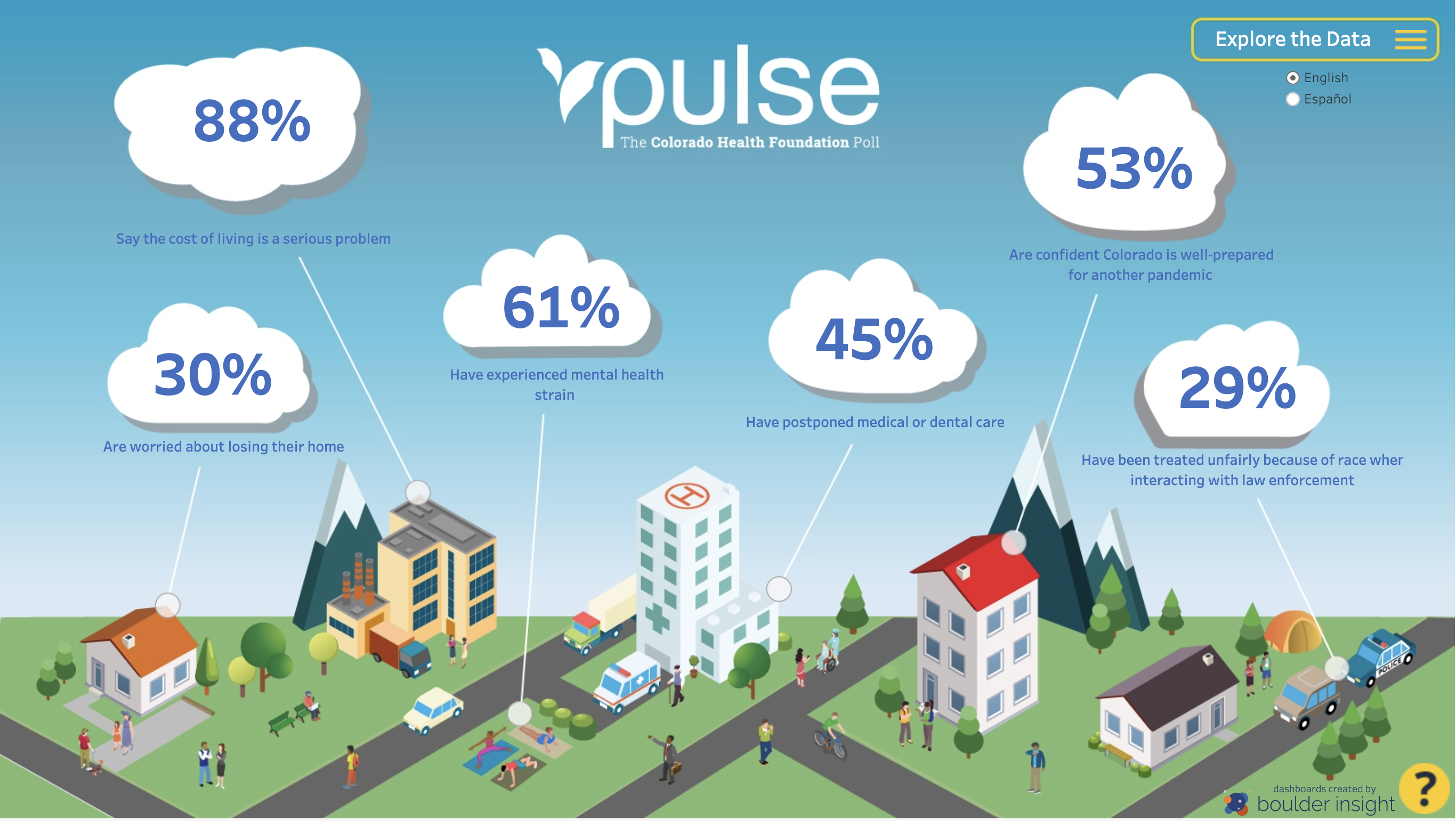















VIZbot
Automatically send interactive or static reports from your Tableau Server to any set of users, on any schedule.

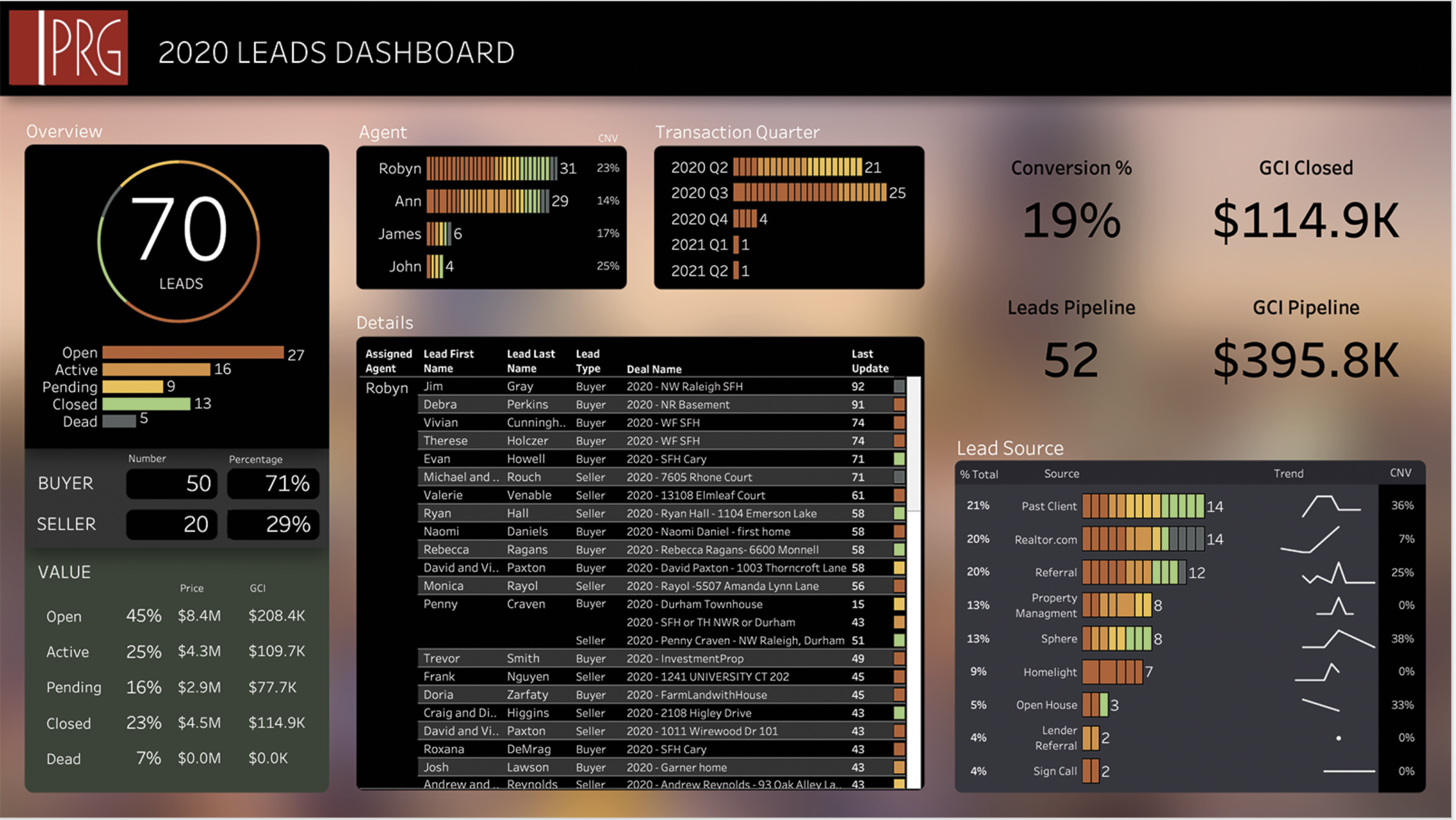
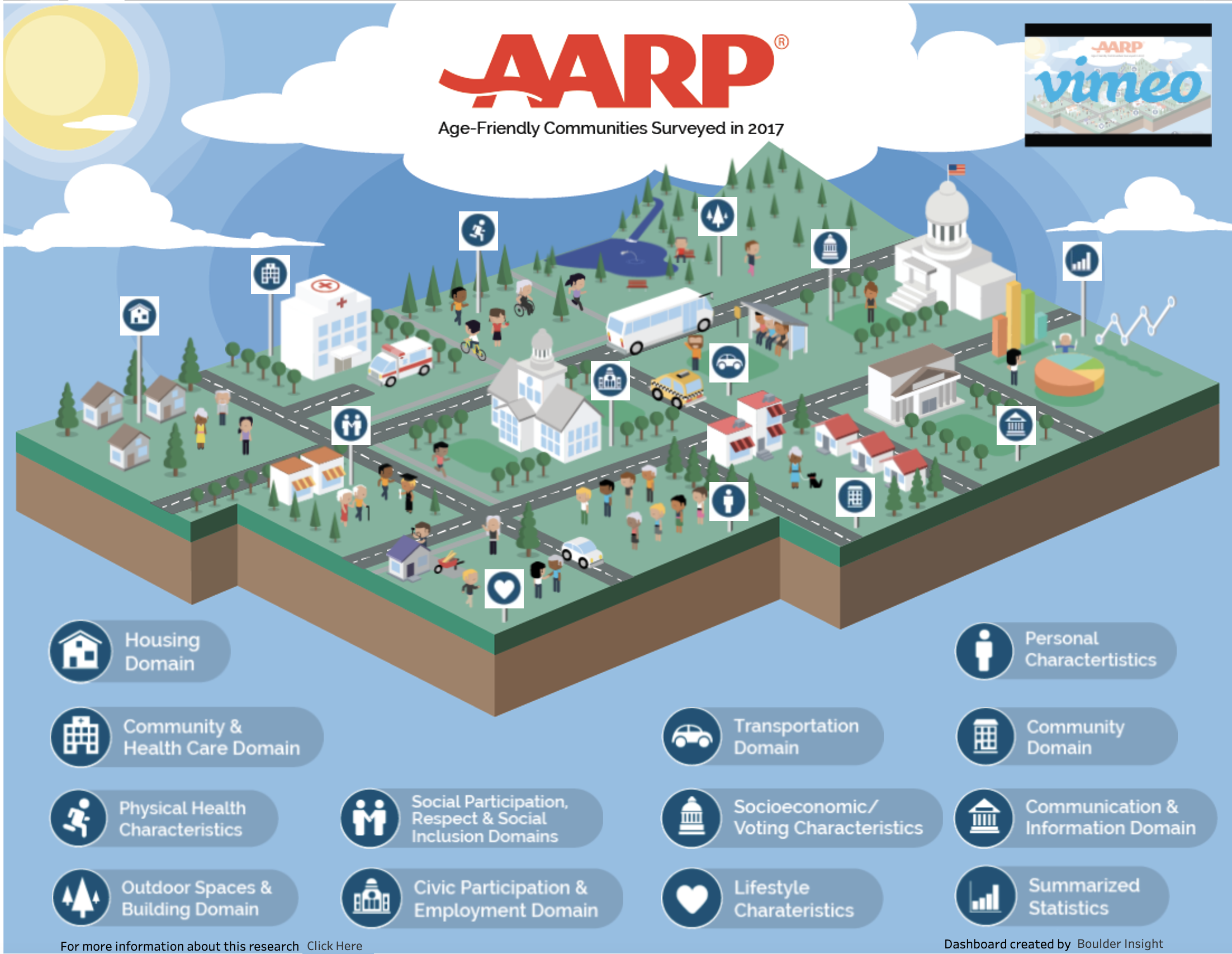
Tableau Templates
Download a suite of pre-formatted, Tableau dashboard layouts. Easily customizable to your organization’s brand and specific structure.

Tableau Server Guard
Use our expertise to maintain optimum performance and protection of your Tableau Server.

Training
Get Tableau Certified Training for any level of Tableau expertise ranging from beginner to advanced. We also offer custom curricula that uses your data.